Hash Tables
Hash tables are a fundamental data structure in computer science used for fast data retrieval. This tutorial will cover the basics of hash tables, their uses, how they work, and the concept of hashing in general.
Introduction to Hash Tables
A hash table, also known as a hash map, is a data structure that stores key-value pairs. It provides efficient insertion, deletion, and lookup operations, typically in constant average time complexity, .
Uses of Hash Tables
Hash tables are widely used in various applications due to their efficiency and versatility. Some common uses include:
- Databases: Implementing indexes to speed up data retrieval.
- Caching: Storing recently accessed data to quickly serve future requests.
- Dictionaries: Implementing associative arrays or dictionaries, where each key is associated with a value.
- Symbol Tables: Managing variable names in interpreters and compilers.
- Sets: Implementing sets, which allow for fast membership testing.
Working of Hash Tables
A hash table works by mapping keys to indices in an array. This mapping is achieved using a hash function. The hash function takes a key and returns an integer, which is used as an index to store the corresponding value in the array.
Components of a Hash Table
- Hash Function: Converts keys into valid array indices.
- Buckets: Array elements where key-value pairs are stored.
- Collision Resolution: Strategy to handle cases where multiple keys map to the same index.
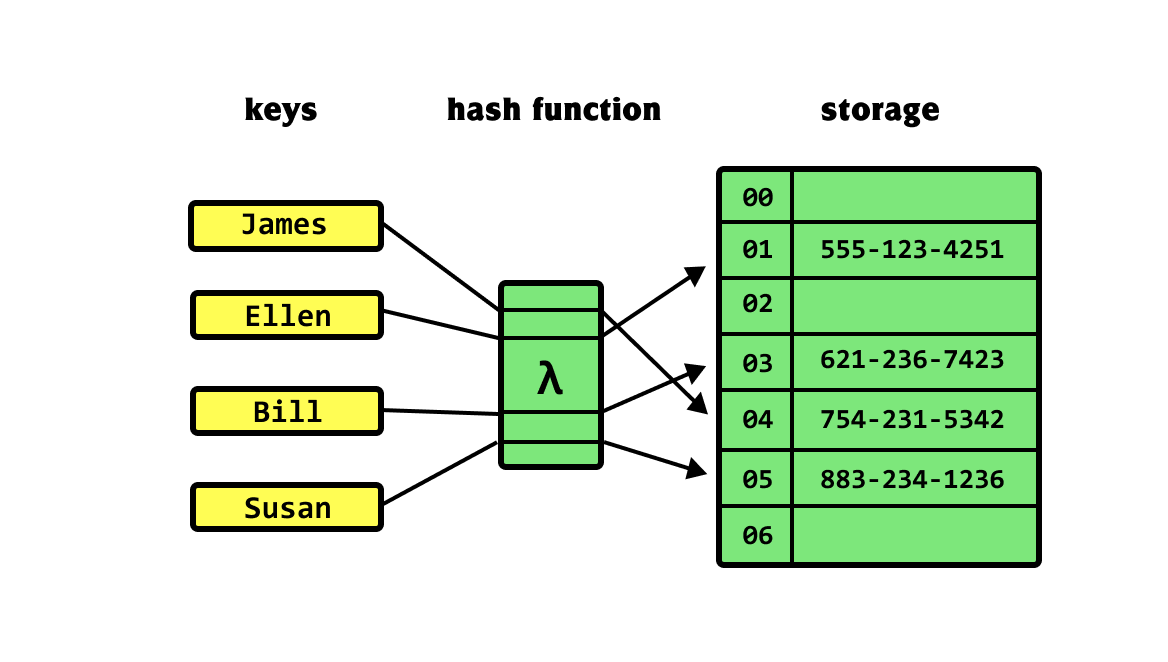
Hash Function
The hash function is crucial for the performance of a hash table. It should be fast to compute and distribute keys uniformly across the array. A common hash function for integers is h(key) = key % N, where N is the size of the array.
Collision Resolution
Collisions occur when multiple keys hash to the same index. There are several strategies to resolve collisions:
- Chaining: Store multiple key-value pairs in a list at each index.
- Open Addressing: Find another index within the array using methods like linear probing, quadratic probing, or double hashing.
Hashing in General
Hashing is the process of converting input data (keys) into a fixed-size integer, which serves as an index for data storage and retrieval. Hashing is widely used beyond hash tables in various fields such as cryptography, data structures, and databases.
Properties of a Good Hash Function
- Deterministic: The hash function must consistently return the same hash value for the same input.
- Uniform Distribution: It should distribute hash values uniformly across the hash table to minimize collisions.
- Efficient Computation: The hash function should be quick to compute.
- Minimally Correlated: Hash values should be independent of each other to avoid clustering.
Common Hash Functions
- Division Method:
h(key) = key % N - Multiplication Method:
h(key) = floor(N * (key * A % 1)), whereAis a constant between 0 and 1. - Universal Hashing: Uses a class of hash functions and selects one at random to minimize the chance of collisions.
Implementing Hash Tables
- Python
- Java
- Cpp
- JavaScript
class HashTable:
def __init__(self, size):
self.size = size
self.table = [[] for _ in range(size)]
def hash_function(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self.hash_function(key)
for i, kv in enumerate(self.table[index]):
if kv[0] == key:
self.table[index][i] = (key, value)
return
self.table[index].append((key, value))
def lookup(self, key):
index = self.hash_function(key)
for kv in self.table[index]:
if kv[0] == key:
return kv[1]
return None
def delete(self, key):
index = self.hash_function(key)
for i, kv in enumerate(self.table[index]):
if kv[0] == key:
del self.table[index][i]
return
# Example usage
ht = HashTable(10)
ht.insert("apple", 1)
ht.insert("banana", 2)
print(ht.lookup("apple")) # Output: 1
ht.delete("apple")
print(ht.lookup("apple")) # Output: None
import java.util.LinkedList;
class HashTable<K, V> {
private class Entry<K, V> {
K key;
V value;
Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
private LinkedList<Entry<K, V>>[] table;
private int size;
@SuppressWarnings("unchecked")
public HashTable(int size) {
this.size = size;
table = new LinkedList[size];
for (int i = 0; i < size; i++) {
table[i] = new LinkedList<>();
}
}
private int hashFunction(K key) {
return key.hashCode() % size;
}
public void insert(K key, V value) {
int index = hashFunction(key);
for (Entry<K, V> entry : table[index]) {
if (entry.key.equals(key)) {
entry.value = value;
return;
}
}
table[index].add(new Entry<>(key, value));
}
public V lookup(K key) {
int index = hashFunction(key);
for (Entry<K, V> entry : table[index]) {
if (entry.key.equals(key)) {
return entry.value;
}
}
return null;
}
public void delete(K key) {
int index = hashFunction(key);
table[index].removeIf(entry -> entry.key.equals(key));
}
public static void main(String[] args) {
HashTable<String, Integer> ht = new HashTable<>(10);
ht.insert("apple", 1);
ht.insert("banana", 2);
System.out.println(ht.lookup("apple")); // Output: 1
ht.delete("apple");
System.out.println(ht.lookup("apple")); // Output: null
}
}
#include <iostream>
#include <list>
#include <vector>
#include <string>
using namespace std;
class HashTable {
private:
int size;
vector<list<pair<string, int>>> table;
int hashFunction(const string &key) {
return hash<string>{}(key) % size;
}
public:
HashTable(int size) : size(size), table(size) {}
void insert(const string &key, int value) {
int index = hashFunction(key);
for (auto &kv : table[index]) {
if (kv.first == key) {
kv.second = value;
return;
}
}
table[index].emplace_back(key, value);
}
int lookup(const string &key) {
int index = hashFunction(key);
for (const auto &kv : table[index]) {
if (kv.first == key) {
return kv.second;
}
}
return -1; // Return -1 if key not found
}
void delete_key(const string &key) {
int index = hashFunction(key);
table[index].remove_if([&key](const pair<string, int> &kv) { return kv.first == key; });
}
};
int main() {
HashTable ht(10);
ht.insert("apple", 1);
ht.insert("banana", 2);
cout << ht.lookup("apple") << endl; // Output: 1
ht.delete_key("apple");
cout << ht.lookup("apple") << endl; // Output: -1
return 0;
}
class HashTable {
constructor(size) {
this.size = size;
this.table = new Array(size).fill(null).map(() => []);
}
hashFunction(key) {
let hash = 0;
for (let char of key) {
hash += char.charCodeAt(0);
}
return hash % this.size;
}
insert(key, value) {
const index = this.hashFunction(key);
for (let [k, v] of this.table[index]) {
if (k === key) {
v = value;
return;
}
}
this.table[index].push([key, value]);
}
lookup(key) {
const index = this.hashFunction(key);
for (let [k, v] of this.table[index]) {
if (k === key) {
return v;
}
}
return null;
}
delete(key) {
const index = this.hashFunction(key);
this.table[index] = this.table[index].filter(([k, v]) => k !== key);
}
}
const ht = new HashTable(10);
ht.insert("apple", 1);
ht.insert("banana", 2);
console.log(ht.lookup("apple")); // Output: 1
ht.delete("apple");
console.log(ht.lookup("apple"));
// Output: null
Time Complexity Analysis
- Insertion: on average
- Deletion: on average
- Lookup: on average
Space Complexity Analysis
- Space Complexity: where n is the number of key-value pairs
Advanced Topics
Dynamic Resizing
When the load factor (number of elements/size of table) exceeds a threshold, the hash table can be resized to maintain performance. This involves creating a new table with a larger size and rehashing all existing elements.
Cryptographic Hash Functions
In cryptography, hash functions are used to secure data. These hash functions are designed to be irreversible and produce a fixed-size hash value for any input.
Bloom Filters
A Bloom filter is a space-efficient probabilistic data structure used to test whether an element is a member of a set. It uses multiple hash functions to map elements to a bit array.
Conclusion
In this tutorial, we covered the fundamentals of hash tables, their uses, how they work, and the concept of hashing in general. We also provided implementations in Python, Java, C++, and JavaScript. Hash tables are a powerful and efficient data structure that play a crucial role in various applications. Understanding how they work and how to implement them will greatly enhance your programming skills and ability to solve complex problems efficiently.