Pooling Layers: Downsampling
After a Convolution Operation, the resulting feature maps can still be quite large. Pooling (also known as subsampling or downsampling) is used to reduce the spatial dimensions (Width x Height) of the data, which reduces the number of parameters and computation in the network.
1. Why do we need Pooling?
- Dimensionality Reduction: It shrinks the data, making the model faster and less memory-intensive.
- Spatial Invariance: It makes the network robust to small translations or distortions. If a feature (like an ear) moves by a few pixels, the pooled output remains largely the same.
- Prevents Overfitting: By abstracting the features, it prevents the model from "memorizing" the exact pixel locations of features.
2. Types of Pooling
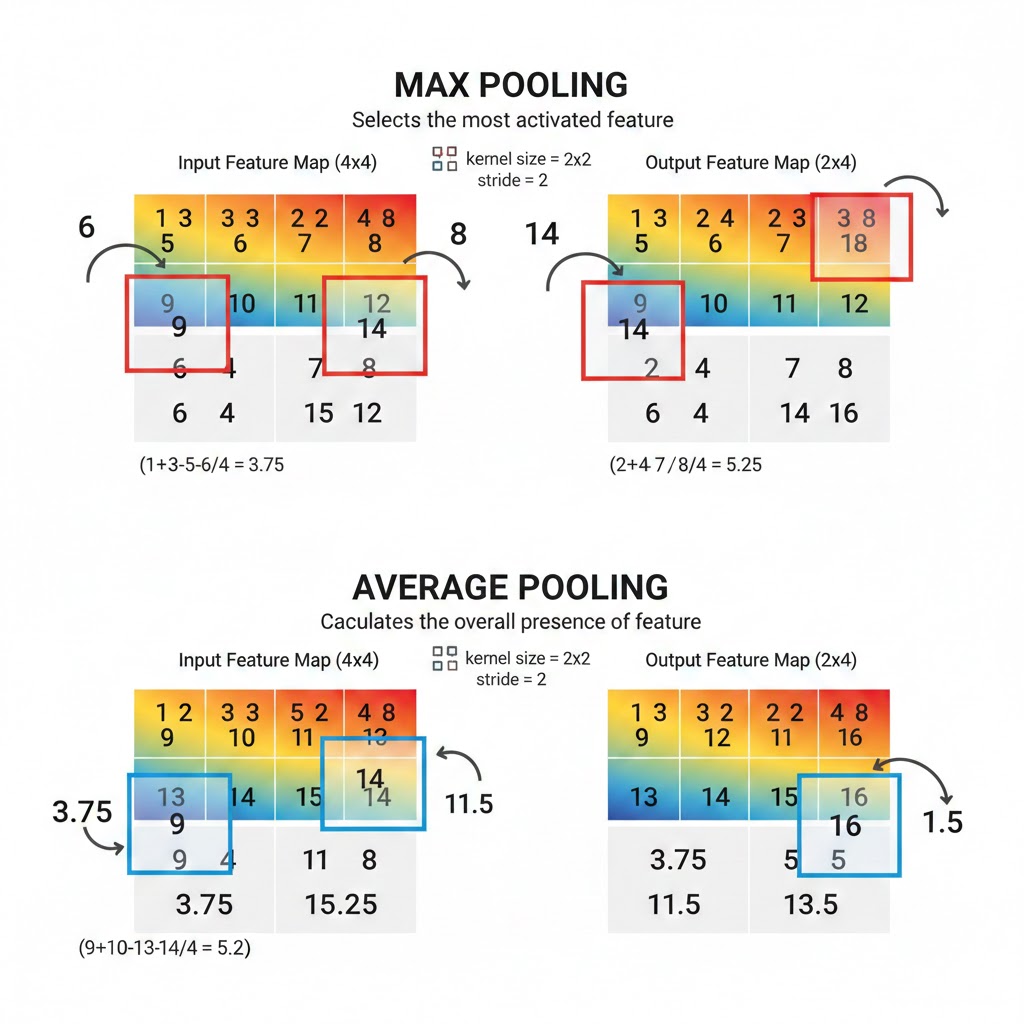
A. Max Pooling
This is the most common type. It slides a window across the feature map and picks the maximum value within that window.
- Logic: "Did the feature appear anywhere in this region? If yes, keep the highest signal."
B. Average Pooling
It calculates the average value of all pixels within the window.
- Logic: "What is the general presence of this feature in the region?"
- Use Case: Often used in the final layers of some architectures (like Inception) to smooth out the transition to the output layer.
3. How Pooling Works (Parameters)
Like convolution, pooling uses a Kernel Size and a Stride.
- Standard Setup: A 2x2 window with a stride of 2.
- Effect: This setup reduces the width and height of the image by exactly half, effectively discarding 75% of the activations while keeping the most "important" ones.
4. Key Differences: Convolution vs. Pooling
| Feature | Convolution | Pooling |
|---|---|---|
| Learnable Parameters | Yes (Weights and Biases) | No (Fixed mathematical rule) |
| Purpose | Feature Extraction | Dimensionality Reduction |
| Effect on Channels | Can increase/decrease | Keeps number of channels the same |
5. Implementation with TensorFlow/Keras
from tensorflow.keras.layers import MaxPooling2D, AveragePooling2D
# Max Pooling with a 2x2 window and stride of 2
max_pool = MaxPooling2D(pool_size=(2, 2), strides=2)
# Average Pooling
avg_pool = AveragePooling2D(pool_size=(2, 2))
6. Implementation with PyTorch
import torch.nn as nn
# Max Pooling
# kernel_size=2, stride=2
pool = nn.MaxPool2d(2, 2)
# Apply to a sample input (Batch, Channels, Height, Width)
input_tensor = torch.randn(1, 16, 24, 24)
output = pool(input_tensor)
print(f"Input shape: {input_tensor.shape}")
print(f"Output shape: {output.shape}")
# Output: [1, 16, 12, 12]
References
- DeepLearning.AI: Pooling Layers Tutorial
- PyTorch Docs: MaxPool2d Documentation
We’ve extracted features with Convolution and shrunk them with Pooling. Now, how do we turn these 2D grids into a final "Yes/No" or "Cat/Dog" prediction?